Background

Row of digital-based slot machines inside a casino in Las Vegas: Source
{kind=link}
LLMs Will Always Hallucinate, and We Need to Live With This . 프롬프트에 수정이 필요할 때, 비관적인 관점에서는 LLM은 슬롯 머신과 같아서 풍선 효과 를 피할 수 없다. 운이 좋으면 안 되던 것이 될 수도 있겠지만, 되던 것이 안 되던 경우도 비일비재했으며, 자연어를 출력하는 LLM의 특성 상 결국 테스트셋 전체를 LLM에 넣어보고 출력을 사람이 검토하는 작업을 정기적으로 수행했다. Batch job을 수행하고 비개발자와 결과를 검토하는 과정에서 개발자들은 엑셀을 읽고 쓰는 일회용 파이썬 코드를 (무수히 많이) 혼자서만 쓰고 폐기했으며, 이 코드는 서비스에서 돌아가는 코드와 입출력이 달라 테스트 결과도 신뢰할 수 없었다. Batch testing은 통과했으나 실제 서비스에서는 체감 성능이 다른 고통스런 경험을 수도 없이 반복하며, 이 비효율을 발본색원할 수 있는 시스템을 AWS 서비스들과 OpenTelemetry 를 이용해 구축하고 있다.
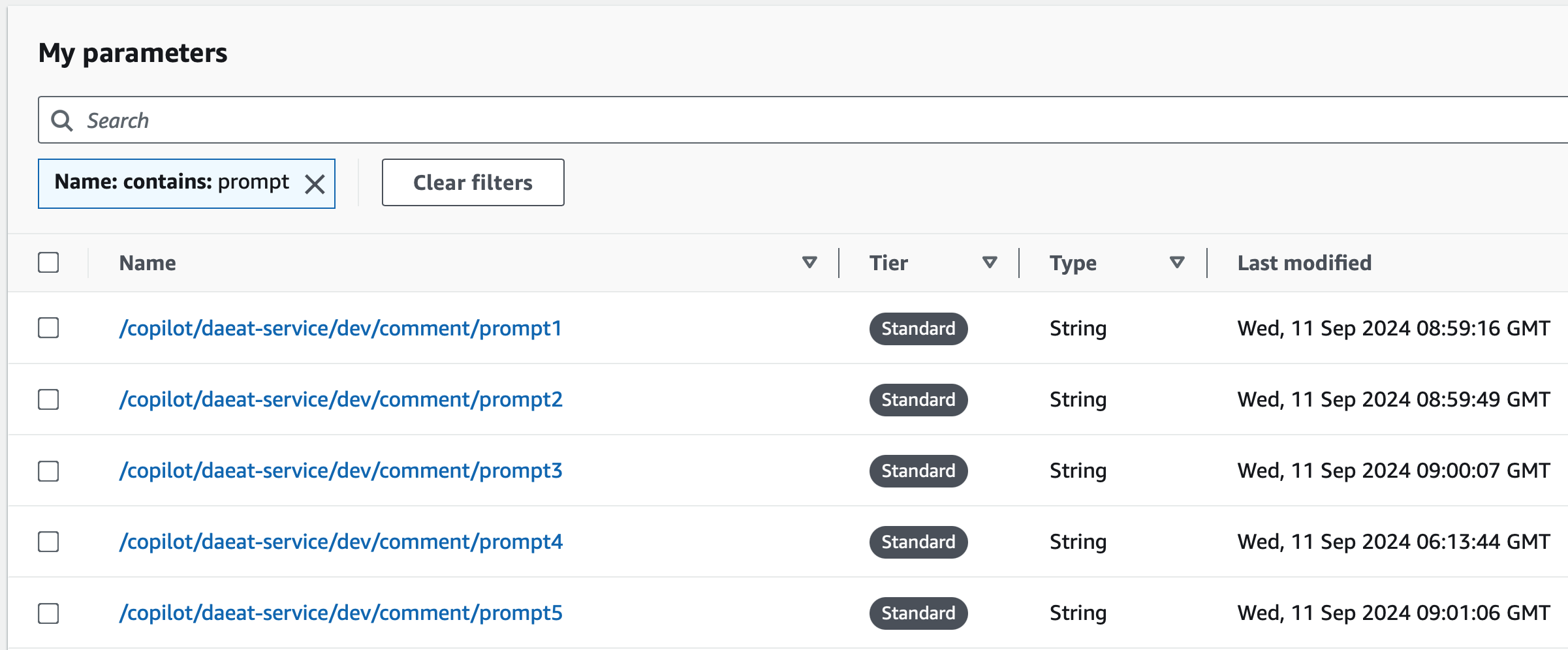
AWS Systems Manager Parameter Store: Prompts
Introduction
git을 이용하면 프롬프트는 코드와 유사하게 취급될 수 있으나, 빌드에 포함되어야 한다는 위험성 때문에 별도의 관리 도구를 AWS 내부에서 찾아보았다. 애플리케이션의 설정을 관리하는 AWS Systems Manager Parameter Store 를 사용해 프롬프트 관리 convension을 정착시키려고 노력 중이다.
Constraints
-
긴 프롬프트는 Parameter 길이의 제약을 받는다.
따라서 프롬프트가 아주 길 경우에는 토막내 관리하는 기법이 필요했다.
-
JSON 예시가 들어간 프롬프트를 Python f-string formatting과 함께 사용할 수 없다.
You can’t include
{{}}or{{ssm:_parameter-name_}}in a parameter valuessm_value.format(foo="bar")와 같이 프롬프트를 가공할 예정이라면ssm_value에 포함된 JSON의{는{{로,}는}}로 Escape되어야 한다. 이는 SSM에 적재될 수 없다.string.Template을 대안으로 사용할 수 있다. SSM에 적재된 프롬프트에 포함된 변수들을 한꺼번에get_identifiers()로 알 수 있어 f-string보다 안전하게 운영할 수 있다.
Usage
-
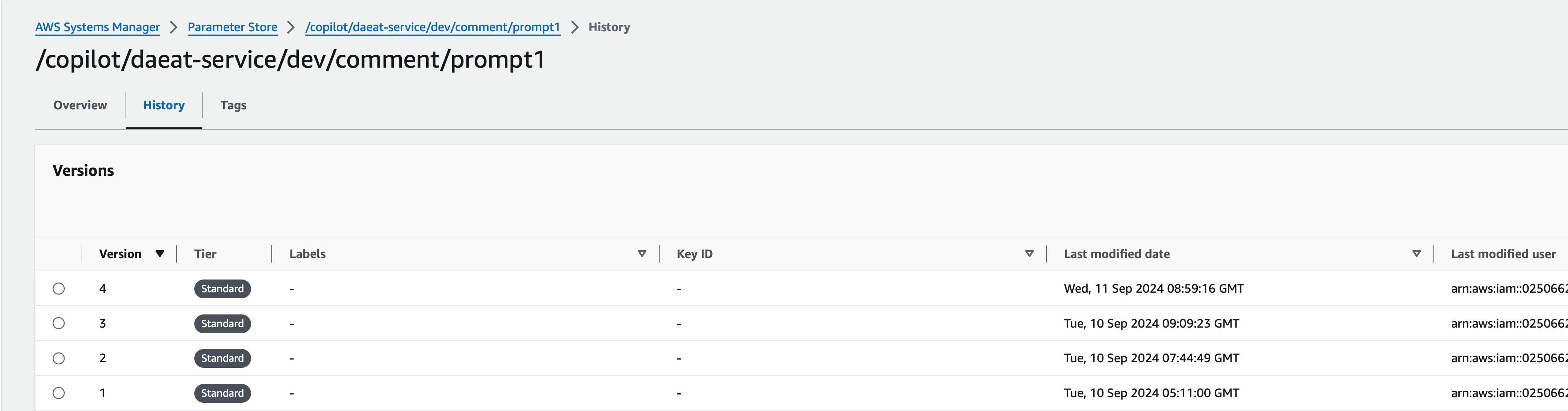
프롬프트를 누가, 언제 변경했는지 변경 이력을 확인할 수 있다.
-
개발 또는 테스트 상황에서 1번의 API 호출로 전체 프롬프트를 한꺼번에 불러올 수 있다: get-parameters-by-path
aws ssm get-parameters-by-path --path <path> -
ECS를 사용한다면, Task definition의
containerDefinitions[].secrets[].valueFrom에 Parameter path 또는 ARN을 넣어 환경 변수로 ECS container에서 프롬프트에 접근할 수 있다.
OpenTelemetry & CloudWatch Logs: LLM Messages
Libraries
- Collect: opentelemetry-instrumentation-openai by traceloop
- Format: structlog
- Store: watchtower
Setup
-
Instrument Open AI SDK
Open AI SDK를 전역적으로 Monkey patch. SDK 소스 코드 를 많이 참조했습니다.
from opentelemetry.instrumentation.openai import OpenAIInstrumentor OpenAIInstrumentor().instrument() -
Setup Logger
structlog를 formatter로, watchtower를 handler로 사용하도록 구성
Docs: Rendering Using structlog-based Formatters Within
loggingimport structlog from watchtower import CloudWatchLogHandler handler = CloudWatchLogHandler( log_group_name="log_group_name", log_stream_name=str(uuid4()), ) logger = logging.getLogger(logger_name) logger.addHandler(handler) logger.setLevel(logging.DEBUG) structlog.configure( logger_factory=structlog.stdlib.LoggerFactory(), ) -
Integrate In-memory exporter
파이썬 오브젝트로 Span을 불러올 수 있도록 In-memory exporter 적용
class InstrumentedOpenAiCompletion(Completions): _instrumentor: OpenAIInstrumentor _trace_provider: TracerProvider _span_exporter: InMemorySpanExporter _span_processor: SimpleSpanProcessor logger = structlog.get_logger(__name__) def __init__(self, open_ai: OpenAI): super().__init__(open_ai) self._instrumentor = open_ai_instrumentor # Step 1: Set up the tracer provider and the InMemorySpanExporter self._trace_provider = TracerProvider() set_tracer_provider(self._trace_provider) # Step 2: Create an InMemorySpanExporter instance self._span_exporter = InMemorySpanExporter() # Step 3: Set up a span processor to export spans using the InMemorySpanExporter self._span_processor = SimpleSpanProcessor(self._span_exporter) self._trace_provider.add_span_processor(self._span_processor) -
Prepare
InstrumentedOpenAiCompletionopen_ai = OpenAI() completion = InstrumentedOpenAiCompletion(open_ai)
Run
-
Call completion
기존 코드 변경은 필요 없습니다.
completion.create( messages=[ { "role": "user", "content": "Say this is a test", }, ], model="gpt-4o-mini", ) -
Export and log spans
clear()를 호출해span_exporter메모리에 저장된 span들을 수동으로 지워줍니다.try: spans = completion._span_exporter.get_finished_spans() completion.logger.info("spans", spans=spans) finally: completion._span_exporter.clear() -
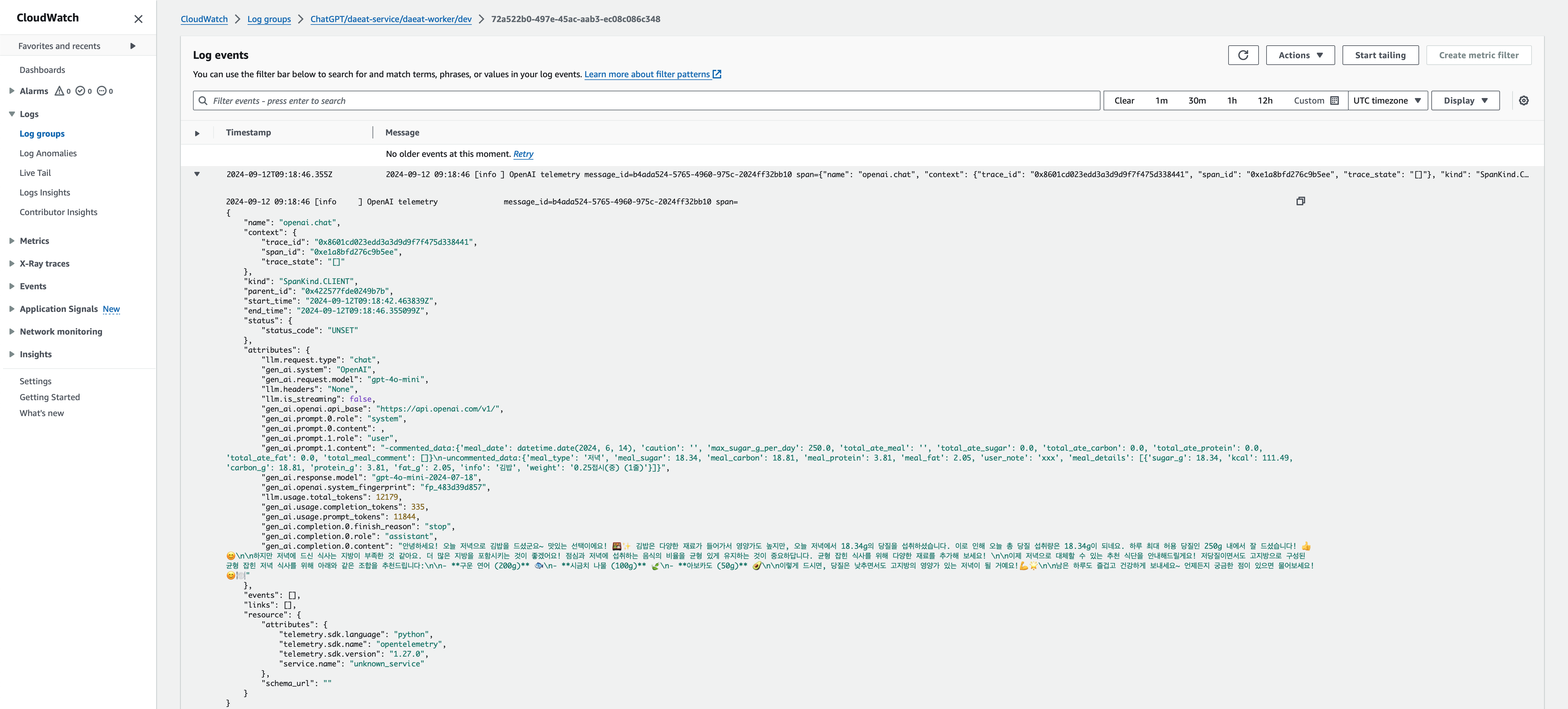
Check CloudWatch
CloudWatch는 Log entry string의 끝에 붙은 JSON string을 구조화함.
prompt와completion의 내용, 토큰 수 등을 CloudWatch에서 확인할 수 있습니다.
CloudWatch Metrics: Rate Limiting
Introduction
Rate limiting 또한 전사적인 문제이나, 공통으로 사용하는 방법론 없이 예상 밖의 동작을 일으킬 수 있는 Exponential backoff를 통한 재시도만 사용하고 있었다. OpenTelemtry에서 영감을 받아 OpenAI에서 오는 Rate limit 관련 Header를 가로채고 적재하고 확인하는 체계를 고안했다.
Implementation
-
Intercept
httpx.ResponseOpen AI SDK는 httpx client로 서버에 요청을 보낸다. Open AI에 http 요청을 보냈을 때,
SyncAPIClient를 기준으로httpx.Response오브젝트는 아래 두 곳에서 가로챌 수 있다.from typing import TYPE_CHECKING if TYPE_CHECKING: from httpx import Response class MonitoredOpenAi(OpenAI): def _process_response(self, *, response: "Response", **kwargs): ... def _make_status_error_from_response( self, response: httpx.Response, ) -> APIStatusError: ... -
Load headers with Pydantic model
from typing import TYPE_CHECKING, List from pydantic import BaseModel, Field, field_validator, ConfigDict from pytimeparse2 import parse if TYPE_CHECKING: from httpx import Headers class OpenAiHeaders(BaseModel): model_config = ConfigDict(populate_by_name=True) @classmethod def model_validate(cls, obj: "Headers"): return super().model_validate(obj) @field_validator("reset_requests_s", mode="before") def convert_reset_requests(cls, v: str) -> float: return parse(v) @field_validator("reset_tokens_s", mode="before") def convert_reset_tokens(cls, v: str) -> float: print(v) return parse(v) limit_requests: int = Field(..., alias="x-ratelimit-limit-requests") limit_tokens: int = Field(..., alias="x-ratelimit-limit-tokens") remaining_requests: int = Field(..., alias="x-ratelimit-remaining-requests") remaining_tokens: int = Field(..., alias="x-ratelimit-remaining-tokens") reset_requests_s: float = Field( ..., alias="x-ratelimit-reset-requests", ) reset_tokens_s: float = Field( ..., alias="x-ratelimit-reset-tokens" ) -
Publish rate limiting headers metrics
References
1초의
StorageResolution으로 직전의 API 호출 통계를 불러온다.import boto3 cloudwatch_resource = boto3.resource("cloudwatch") cloudwatch_metric = cloudwatch_resource.Metric("namespace", "remaining_tokens") cloudwatch_metric.put_data( MetricData=[ { "MetricName": key, "Value": value, "Unit": "Seconds" if key.endswith("_s") else "None", "Dimensions": [{"Name": "ApiKeyHash", "Value": api_key_hash}], "StorageResolution": 1, } for key, value in OpenAiHeaders(response.headers).model_dump().items() ] )
Conclusions
- 개발 중인 서비스에 요청만 많이 보내면 모든 입출력을 기록할 수 있기 때문에 일회용 입출력 코드를 많이 줄이고 Production과 동일한 환경에서 Batch testing을 진행할 수 있을 것으로 기대합니다.
- HyperClova API도 httpx를 이용해서 호출할 수 있습니다. opentelemetry-instrumentation-httpx 을 이용하면 LLM 입출력과 Rate limiting 문제를 한꺼번에 해결할 수 있을 것으로 예상합니다.